
# C 笔记
# 字符串
# 数组越界
定义字符串时定义了字符串的大小 但是会发现虽然定义的是这么大 不过还是可以一直输入 并且输出的时候也不会有限制 直接就输出了输入的内容
点击查看原因
这涉及到了数组越界的问题 定义字符串时给的大小 然后系统就分配了这么大给字符串 但因为在内存中地址是连续的 所以后面多出来的字符就占用了后面的内存(即数组越界) 这样做是很危险的 如果后面存的是重要数据的话 会直接覆盖(似乎美国一个火箭就是这么爆炸的) 可以在输入是加以控制 直接输入scanf("80s",ch)来解决问题# 字符串获取空格
输入字符串时 如果使用 scanf 会发现只要一遇到空格 字符串的输入便视为结束 而使用 gets 就可以进行正常输入 (可以包含空格) 但是 gets 无法对数组越界进行控制与检查
点击查看原因
我们可以使用scanf("%10[^\n]",str)来处理 意思即是 只能输入十个字符 并且最后以回车结尾 存入str数组中# 变量范围 (PTA 有感) (错的)
算是狠狠的教训了我一顿 原以为数据大小完全会用不到边 可是在考试里面它偏偏就会出这种题
题目贴出来
题目描述
给定区间 [-2 的 31 次方,2 的 31 次方] 内的 3 个整数 A、B 和 C,请判断 A+B 是否大于 C。
输入描述
输入第 1 行给出正整数 T (<=10),是测试用例的个数。随后给出 T 组测试用例,每组占一行,顺序给出 A、B 和 C。整数间以空隔。
输出描述
对每组测试用例,在一行中输出 “Case #X: true” 如果 A+B>C,否则输出 “Case #X: false”,其中 X 是测试用例的编号(从 1 开始)。
输入例子
4
1 2 3
2 3 4
2147483647 0 2147483646
0 -2147483648 -2147483647
输出例子
Case #1: false
Case #2: true
Case #3: true
Case #4: false
代码如下
1 |
|
# 数组的动态分配引出的问题 —— 可变长数组
可变长数组实际上就是变量数组,即数组的大小可以先不给出 而由用户实际需要而给出
例如
1 |
|
此时数组 a 的大小是由用户输入的 n 来确定的
可变长数组这个名字有迷惑性,一开始我以为通过对 n 的反复赋值,可以动态的调整数组 a 的大小 一开始设计的例子正好可以运行 (因为一开始设计了一个 while 循环 每次都输入 n 每次都重新定义数组 a 再加上每次都会重新对 a [n] 重新赋一次值 发现不了数组重新定义的变化 所以看不出有什么问题 曾经一度我还想把这个代替 malloc 来用 (极力证明这种方法可以) 后来重新写了一个合理的例子 发现问题了
1 | /*原来的例子*/ |
运行结果如下:
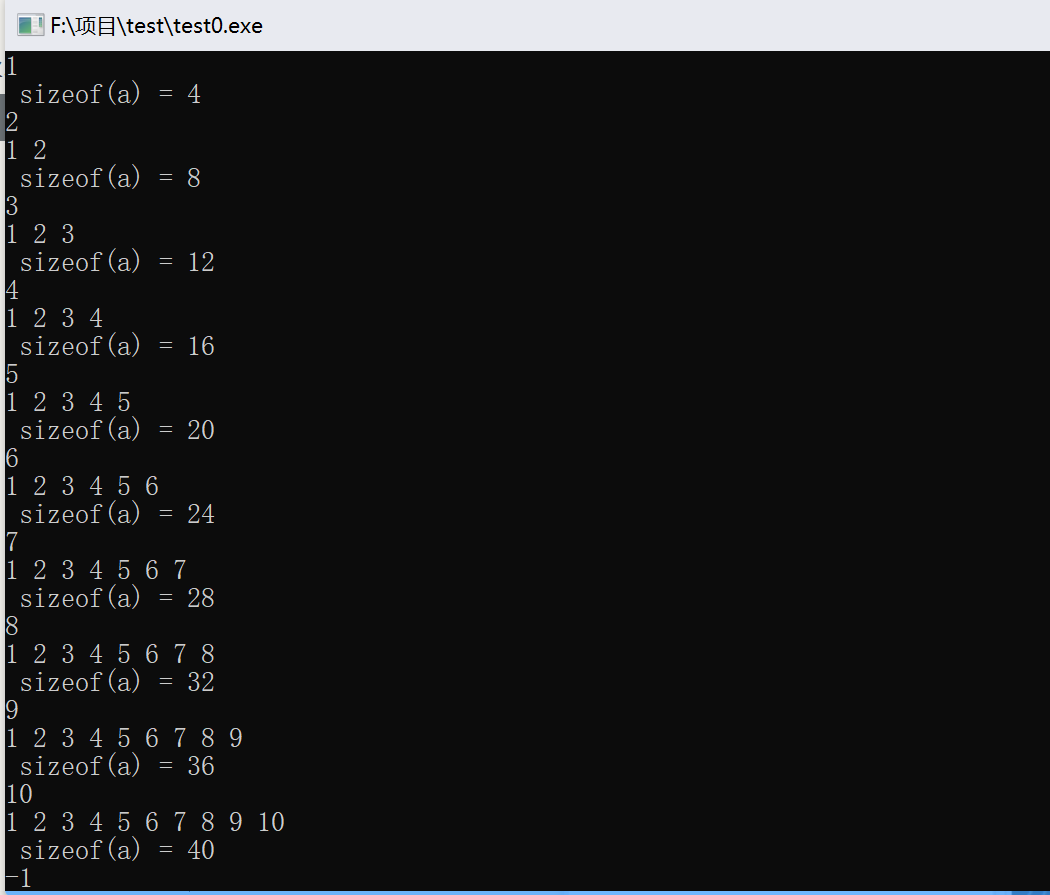
重新写的例子如下:
1 | /*重新写的例子*/ |
运行结果如下:
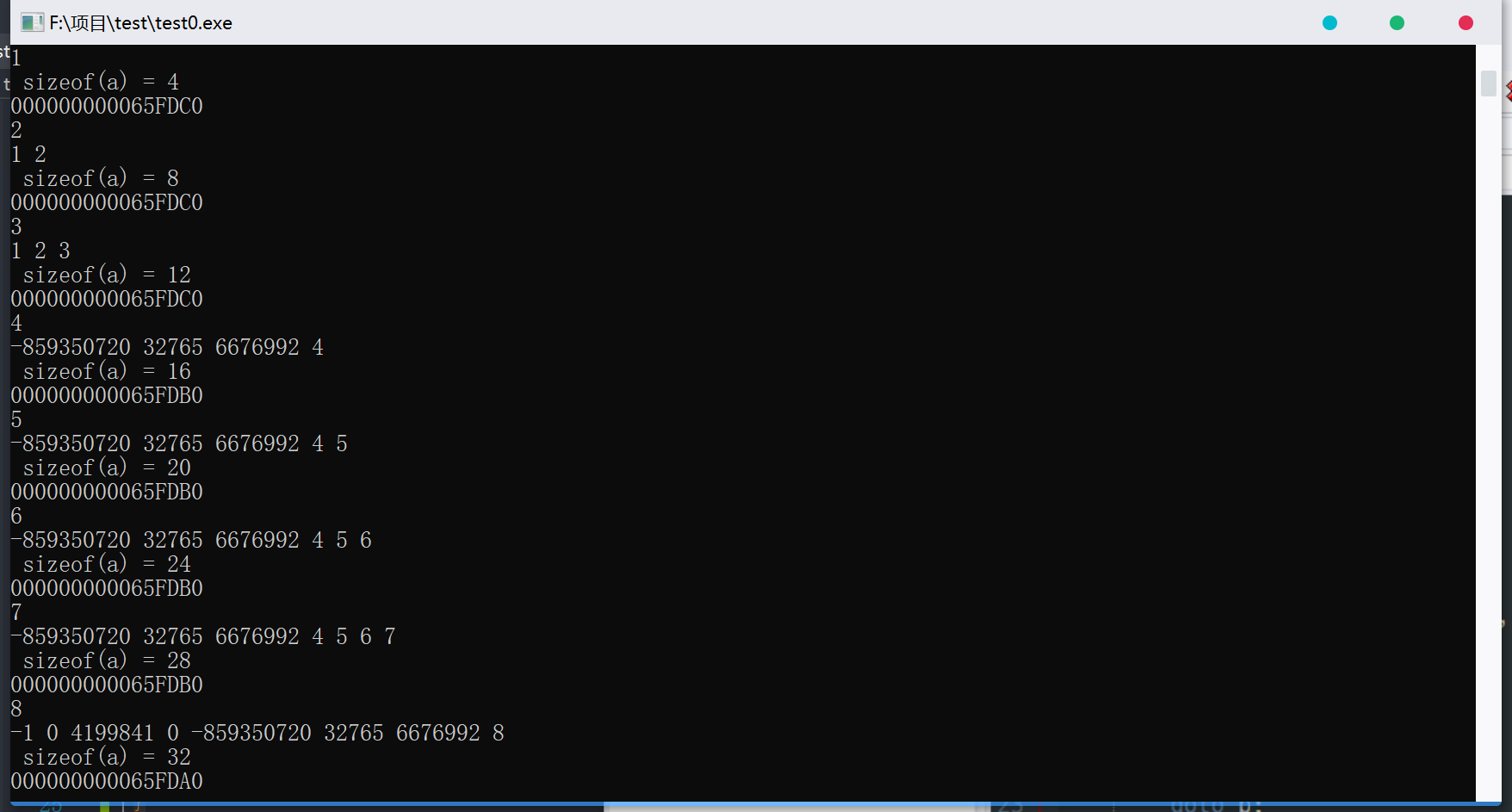
结果发现 每输入 4 的倍数 a 数组的首地址都会改变 导致已经赋予数组的值改变 所以证明这种方式还是不靠谱 最多临时用一用 (dev 上面运行的 vs 上面编译不了 一直报错)
# 动态分配 malloc calloc 以及 realloc
malloc 动态分配空间 realloc 扩展或者缩小空间 calloc 动态分配空间并初始化
# 实例
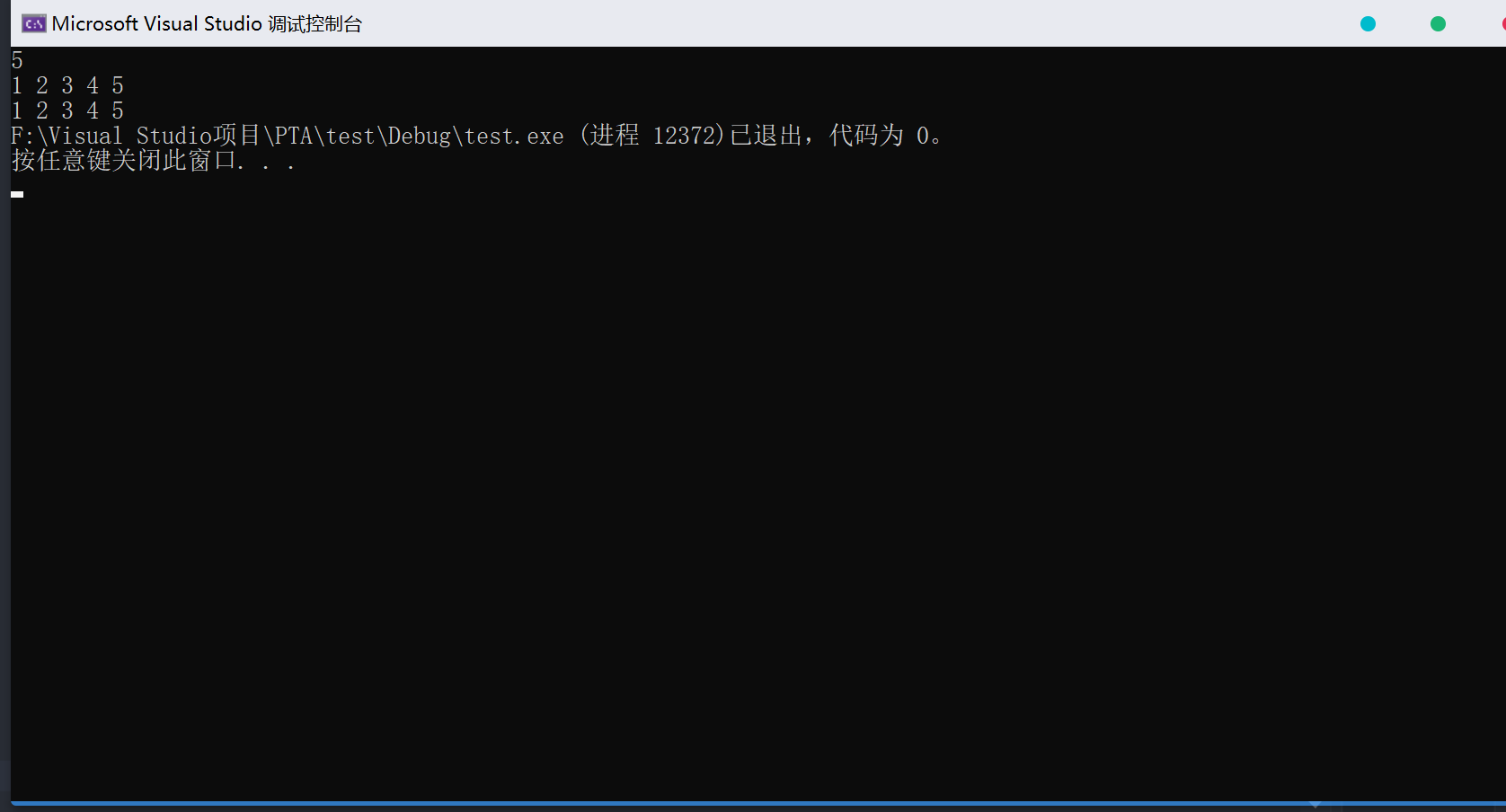
1 | /* No.1 malloc简单使用*/ |
运行结果 :
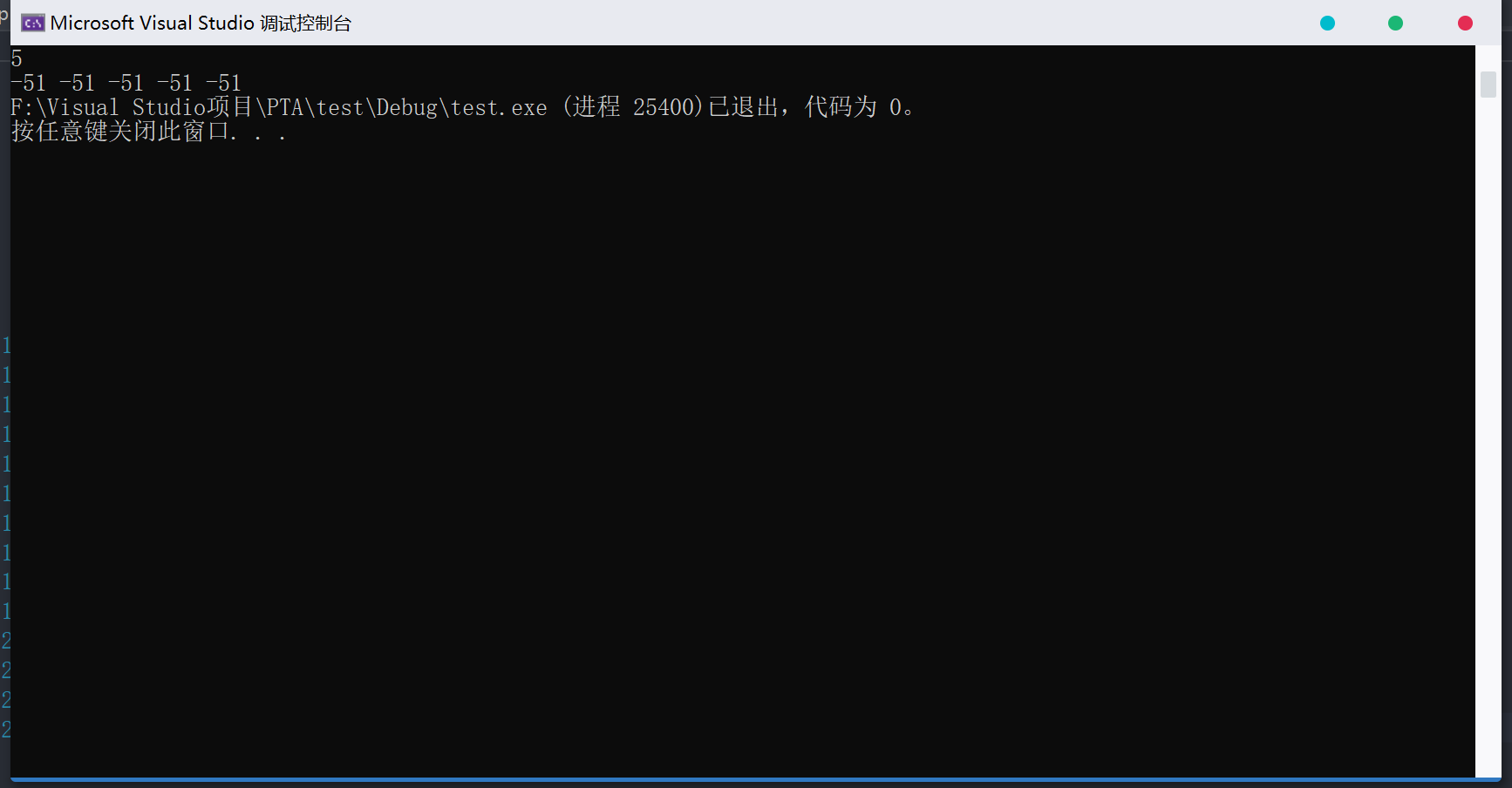
1 | /*No.2 未对malloc后的数组进行初始化(用来对比calloc)*/ |
运行结果 :
1 | /*No. 3 calloc*/ |
运行结果 :
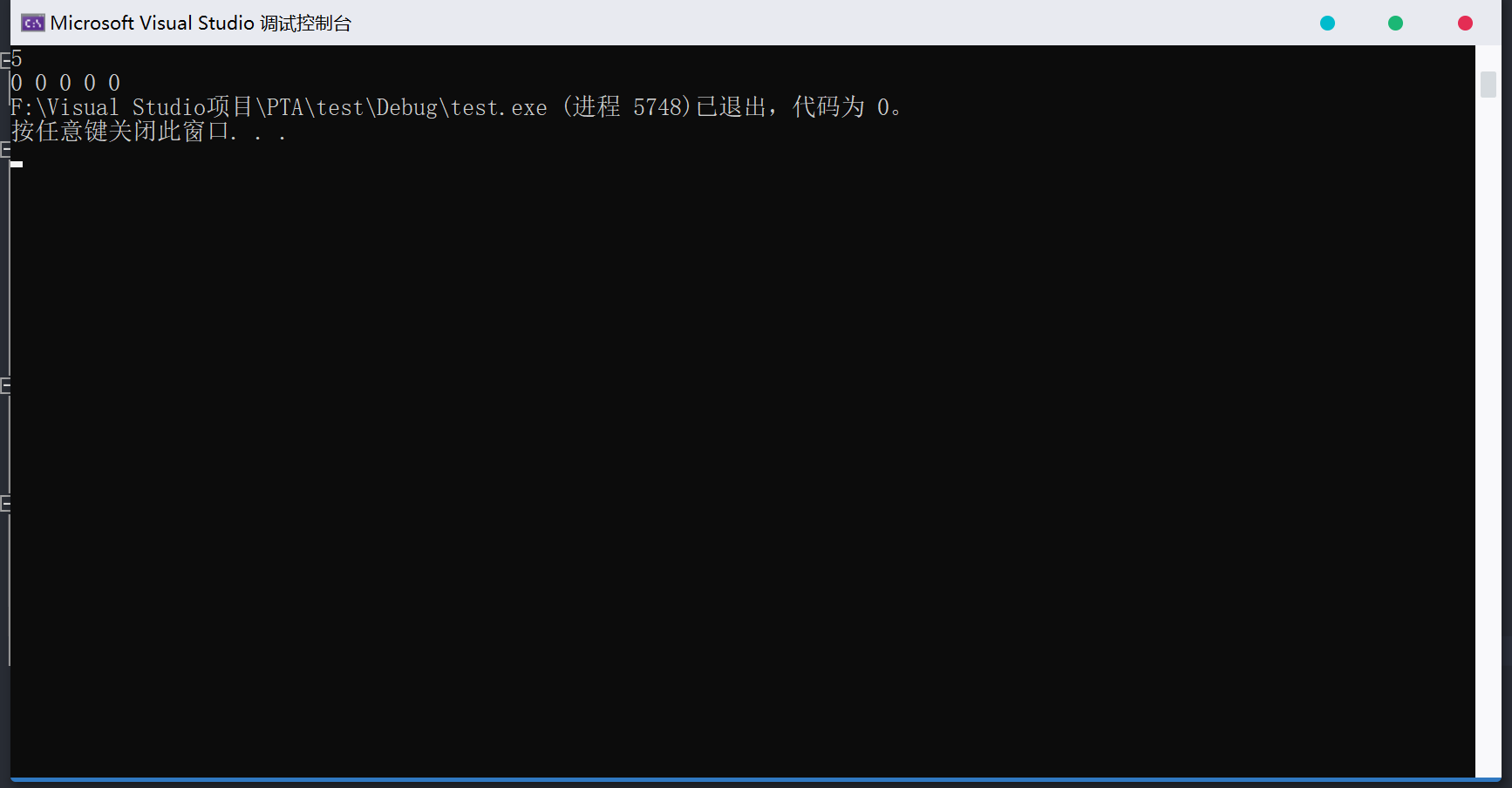
1 | /*No. 4 realloc扩容*/ |
运行结果 :
# 关于字符型变量处理小于 - 128 的负数的方式以及字符型变量取值范围的由来及原理 (听起来是不是很高级🐂🍺)
最开始的起源是由于这个题:
1 | /*6.写出打印结果_______*/ |
输出结果是 255 我人傻了
这个题涉及到进制转换后的原码 反码 补码相关的知识
首先 为什么 char 类型的变量的范围是 (-128,127) 呢 char 变量存放在计算机中是以二进制的方式来存储的 所以规定 char 类型变量存放 8 位二进制 其中首位为符号位 那么可以表示的范围就是 (-127,127) (为什么出现反码和补码这里不解释了) 但是就会出现一个问题: 1000 0000 表示什么呢 按理说应该是 - 0 但是 0 已经可以用 0000 0000 来表示了 出现两个零明显是不合适的 于是我们就想到了 - 128 它的源码是 1000 0000 补码是 1 1000 0000 但是 char 类型只能存放 8 位二进制 所以就变成了 1000 0000 再加上在参与运算的时候 将 1000 0000 视为 - 128 并不会出现问题 所以就把 1000 0000 当成 -128 使用了
但是 1000 0000 按照一般的二进制规律表示为 0 所以 C 语言规定如果 char 类型变量中出现了 1000 0000 就把它看成是 - 128
那超过 127 或者低于 - 128 的时候又怎么办呢 我们发现 当赋予一个字符型变量为 - 129 时 % d 输出时输出的是 127 为什么会是这种结果呢 因为 - 129 的二进制为 10 0111 1111 char 类型丢弃前面两位就变成了 0111 1111 也就是 127 了 超过 127 或者低于 - 128 的数据就是被这样处理的
回到那个题上面来 题中的数组的值依次为 - 1,-2,……-128, 127 (原来 - 129 处理之后),126 (原来 - 130 处理之后),125,……0,1,2,……………… 就这样一直循环下去
但是为什么最后 strlen 的值是 255 呢 首先要弄懂 strlen 的原理
strlen 是用来查询字符数组长度的 具体原理是通过对 a [i] 的遍历 直到找到一个 a [i] == ‘\0’(对应 ASCⅡ 码为 0000 0000 即 NUL) 默认的字符数组最后面都会加上‘\0’ (在还有空间的时候 但如果 a [5] = {1,2,3,4,5} 那么这样就没有空间来存放‘\0’了) 所以 strlen 一直找 直到第 256 项为‘\0’ 长度被确定为 255
由此 这道题彻底搞懂了✌
附图
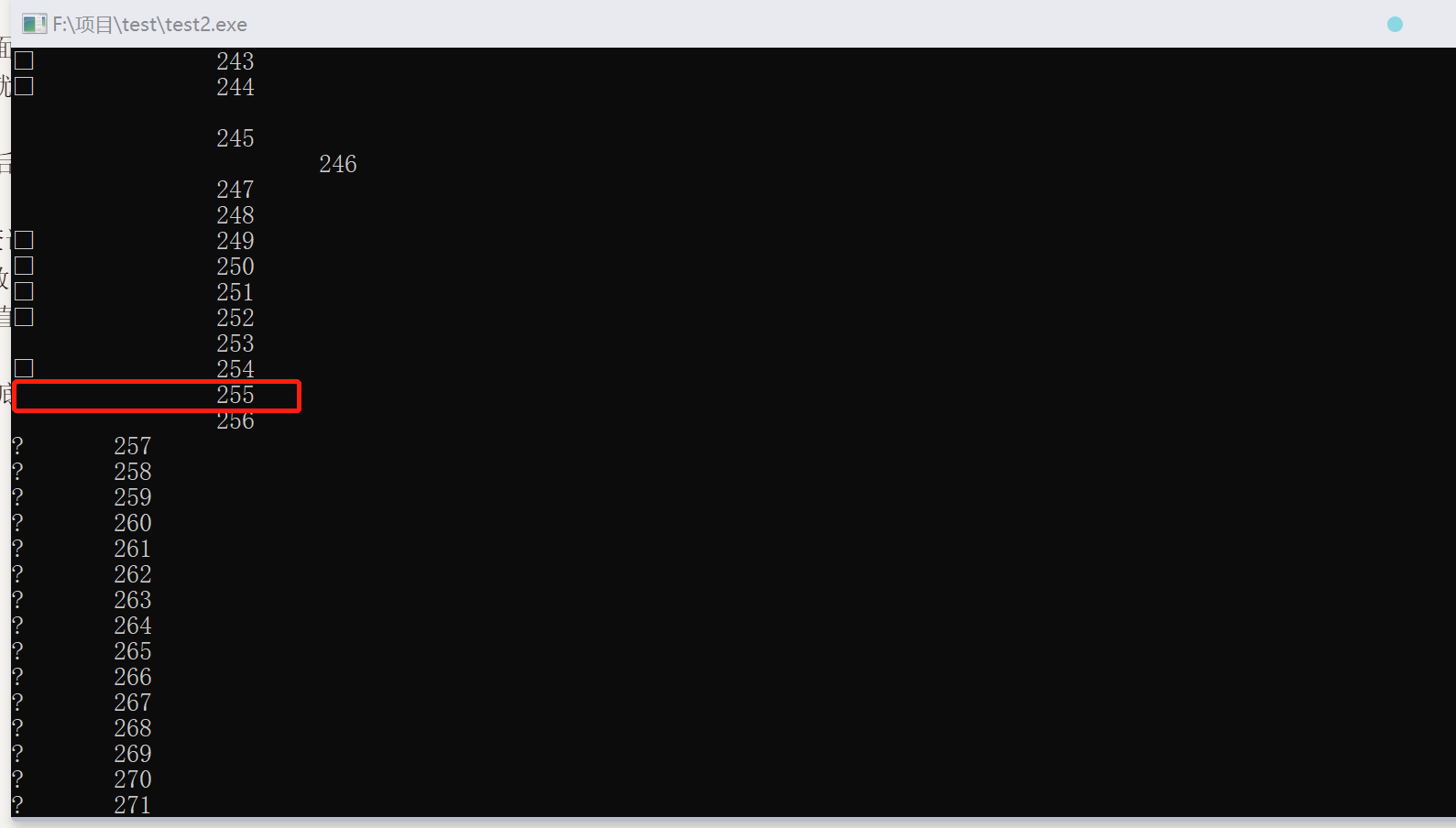
黑色方框是因为在 ASCⅡ 码中代表的是一个操作 不是一个字符 所以没法显示
# 给初始化为 NULL 的结构体指针赋值报错问题
在我写学生管理系统的时候出现了一个问题:
1 | /*这里的temp,p1,p2都是结构体指针*/ |
但是运行的时候报错:
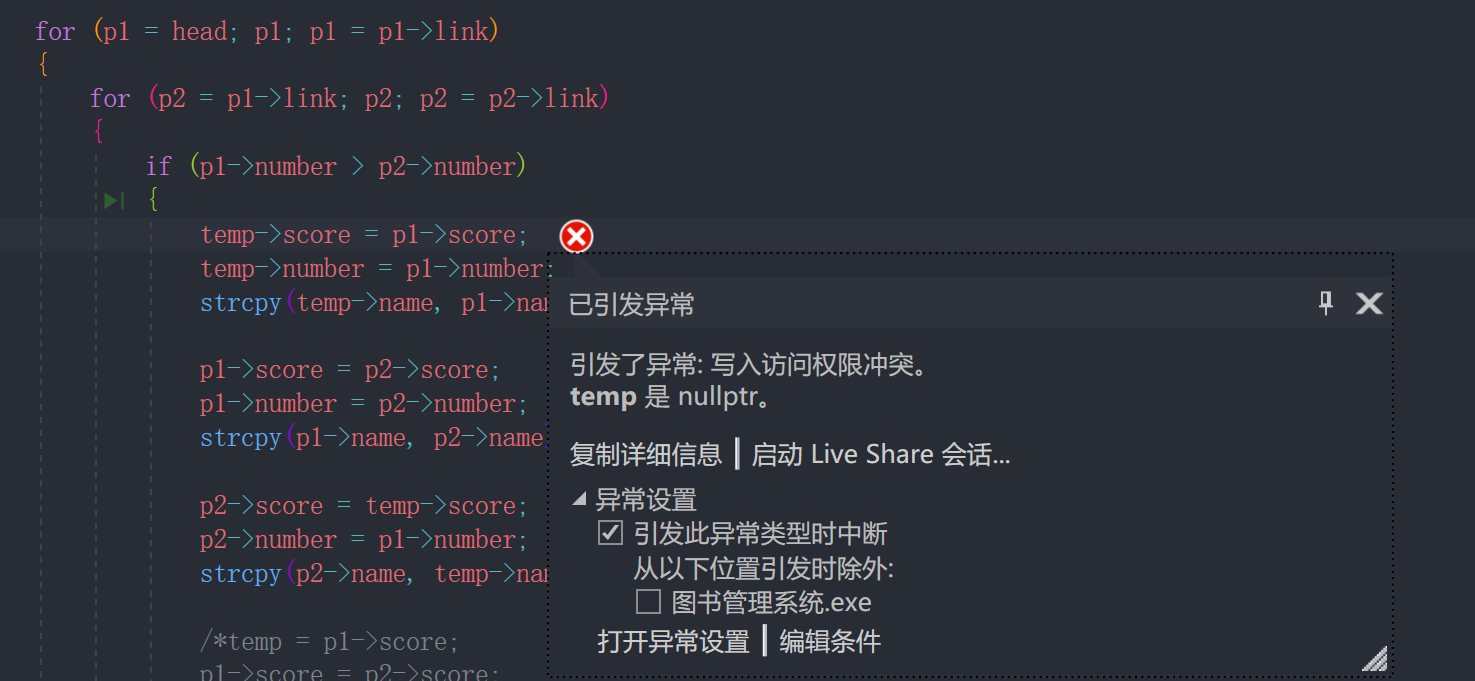
一开始还没有意识到错误 于是去 CSDN 查了一下
不是什么很难理解的东西:之前已经令 temp = NULL, “temp->score” 中 “temp->” 本来就是 (*temp.score) 的意思
temp = NULL 那么 **temp * 就指向 0 temp-> 里面什么都没有 就出错了
解决方法:使用动态分配 malloc 给 temp 个地址就好了
例:
1 | temp = (struct node*)malloc(siezof(struct node)); |
# 关于字符型指针变量赋值时的问题 (typedef 与 #define 的区别和联系)
起因:
1 |
|
报错:

于是以为是 typedef 出现了问题
然后查出了这个:
typedef 和 #define 有相似之处,但是在一些复杂场景,达到的效果又大不相同
typedef 代表着创建一个新类型 (在已有的类型基础上), 所以支持以下操作
1 | typedef char* STR; |
得到效果: p1 与 p2 都为 char 型指针
#define 仅仅是替换字符
1 |
|
得到效果:和 char *p1,p2; 一样
之前知道 char *a 这种类型是可以把 a 当作字符串来用的 (因为数组名本质上也就是一个指针) 所以我们在这里要把 a 看成是一个字符串
字符串的赋值应该用双引号 这里双引号起到了两个作用
- 在常量区申请一段空间存放双引号里面的内容
- 在字符串的尾部添加‘\0’
- 返回地址
而这些是单引号所不能达到的
但是如果直接使用 char a 则是可以的 例如下:
1 |
|
# 我要通过!(PAT 习题)
原题如下 :
“答案正确” 是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的 “答案正确” 大派送 —— 只要读入的字符串满足下列条件,系统就输出 “答案正确”,否则输出 “答案错误”。
得到 “答案正确” 的条件是:
- 字符串中必须仅有 P、 A、 T 这三种字符,不可以包含其它字符;
- 任意形如 xPATx 的字符串都可以获得 “答案正确”,其中 x 或者是空字符串,或者是仅由字母 A 组成的字符串;
- 如果 aPbTc 是正确的,那么 aPbATca 也是正确的,其中 a、 b、 c 均或者是空字符串,或者是仅由字母 A 组成的字符串。
现在就请你为 PAT 写一个自动裁判程序,判定哪些字符串是可以获得 “答案正确” 的。
这个题远远没有想象的这么简单 题中蕴含了很大的信息量 而且隐藏的很好 我做的时候怎么做都不对 后来查了做法才知道有这么多的信息都没有接收到
首先审题 :
第二个条件 xPATx 是正确的 其中 P 前面和 T 后面都有同一个字母 “x” 这不仅代表了由 A 组成的字符串或者空字符串 而且包含这两个是同样长度的字符长度的信息 也就是说 当 “x” 为零时 即 PAT 是正确的 AAPATAA 也是正确的
第三个条件 aPbTc 是正确的 且 aPbATca 也是正确的 我们假设有一个字符串既满足二条件也同时满足三条件
提炼一下三条件 当 P 与 T 之间多加一个 A 时 T 后部多出一个与 P 前面数量的 A 也是正确的
再把二条件带进来 就可以得出以下等式
(a 表示为 P 前面的 A 的数量 b 表示 P 与 T 之间的 A 的数量 c 表示 T 之后的 A 的数量)
所以说 正确的做法应该是用数组完整的接收一个字符串之后再对其进行判断 而不该是用 getchar ()
1 | /******我的做法*******/ |
1 | /*********正确做法*********/ |